Semantic Versioning for ML models
Semantic versioning makes it easy to be explicit about changes in software releases. Could it also benefit machine learning models? Let’s explore this thought experiment.
Semantic versioning defines the version number of a software release based on what changed in the public interface. It’s not about size, difficulty, or marketing; it’s all about differences in the public interface. More precisely, it’s firstly about compatibility with previous versions and secondary about added features or fixed errors.
Could we also apply this to Machine Learning (ML) models? Could this improve communication about model upgrades and their compatibility with previous versions?
ML models also have a public interface with which we interact. We invoke them using some interface and refer to upgrades with a different label. Dashboards and reports then reference models using this label. That label is simply a version identifier, which could be an increasing number (v37), a name (John’s DL model), and sometimes includes some creation date information (forecasting-model-aug-2023).
Semantic versioning’s simplicity and explicitness could potentially clarify and standardize this. Before we apply semantic versioning to machine learning, let me briefly recap semantic versioning.
Semantic versioning, a focus on the public interface
Semantic Versioning requires one to be explicit regarding the public interface of software [1], also known as the API. That API’s form depends on how the software system is delivered. The public interface can be the REST endpoint for services, the classes and methods for libraries, or the options and arguments for a command line interface. Given a public API, a version number consists of 3 digits (i.e., 1.2.3), representing the major, minor, and patch versions. Optionally, it can also contain a suffix (like -alpha). Increments in the versions are done based on the impact of the changes to the public API, focussing on the compatibility with the previous version:
- A Major version upgrade means the public API got breaking (non-backward compatible) changes. API users must change how they use the software (even if it is only on some parts).
- A Minor version upgrade means the software received improvements or new features in a backward-compatible way. Users do not need to update their side because the existing features still work like they did (the modifications were backward-compatible). The changes just introduced new possibilities that the users could use if they wanted.
- A Patch version upgrade means the software improved non-functionally or got fixes for unintended behavior (bugs). It could be as simple as a change in the documentation. Using the new patch version should always be safe and recommended, as it would include bug fixes that don’t require consumer modifications.
Consuming semantic versions (of your dependencies)
When you use this software, you depend on a particular version. This dependency consists of a specific Major version (the API you’re compatible with) and a minimal Minor version (with the features you use). If you know a particular patch version fixes a bug impacting you, you can also require that patch version, but in general, you use the latest available one. In practice, bugs get fixed along with new features. Thus, you might need a higher minor version so as not to be impacted by the bug.
If your dependency adheres to semantic versioning, it is easy to know which new releases are compatible with your existing implementation. You can safely upgrade to an arbitrary higher minor or patch version, as those should be backward compatible. Of course, as with any change, tests and validation of the result are recommended. Here lies the power of tools like Dependabot and Renovate, which will create a merge request on your behalf, upgrade your dependencies to a higher version, run your test suite, and optionally automatically merge it on success.
Simplifying ML model deployment decisions
Being explicit about code compatibility thus has its value, but how would that benefit ML models? Well, when you release a new model, there are typically some decisions both you and the model users need to make:
- Does the model need a new REST endpoint URL (/v2 instead of / v1), or can you just put it behind the current endpoint?
- Should you run the new model next to the previous model before acceptance?
- Do you need to modify data pipelines to provide different data (or in a different format)?
- Do client services need to update their invocation arguments?
- Do you want to distinguish the new model from the previous model in dashboards and reports?
We can simplify these and similar decisions by applying Semantic Versioning’s definitions of Major, Minor, and Patch versions, letting them indicate breaking changes, backward-compatible improvements, and fixes. But what can change with a newly deployed model?
Changes in the ML model interface
Consumers of the ML model can invoke the model in various ways; the model API can be a REST service, a command line utility, a library with model artifacts, or just the model artifact. The following figure shows, on an abstract level, how a machine-learning model could be created and served behind an API:

The public interface to the model, identified by the API, hides most details from the model users. However, the components behind it do influence various aspects of the model. Changes in those components propagate into the model API. Therefore, let us investigate what can change with a new model version:
- The samples for which a model can qualitatively create predictions are referred to as the domain or feature space. This space depends on the range of input values the model has been exposed to in combination with the model training approach. Therefore, a different training set or approach can increase, decrease, or shift the domain.
- Input features are the attributes of the records in the domain used in the prediction. New model releases can require new features, ignore some previous ones, or expect the values to be in a different format or range.
- When you retrain a model, perhaps with different hyperparameters or with a different library, its behavior changes. It should create more accurate predictions, though the improvement can differ per predicted sample.
- The model output is of a certain kind (numerical, binary, or categorical) and lies within a specific range of values. The possible output values might change with the new model.
- The model execution needs particular libraries to run and or interact with the model. If you switch from SKlearn to Lightgbm, you’ll need a different library for inference. This change is hidden from the user in the above example with an API but becomes relevant when the model is provided as a serialized object.
Thus, in short, a new version can change expected inputs or the outputs it generates:
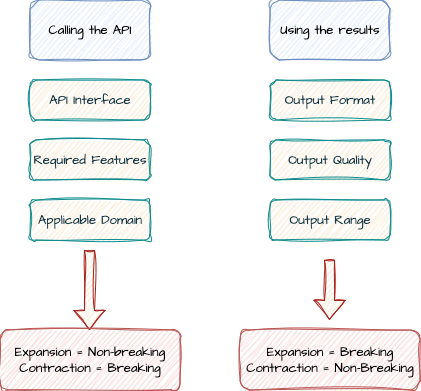
Semantic versioning for ML models
Changes in these aspects could require the model user, the consumer, to modify their side. Let us identify what kind of modifications lead to either major (breaking changes), minor (backward compatible changes), or patch versions:
- Breaking changes can include reducing the domain (aka feature space, eligibility, or generalizability), adding additional required input features, using a different REST interface, or resulting in model outputs outside the previous domain.
- Backward-compatible changes can include a new model training set, a different model library, increasing the applicable domain, making some input features optional, additional REST endpoints, and anything else that requires the model to be distinguishable from the previous in dashboards.
- Patch version upgrades consist of all changes that aren’t important enough for consumers to distinguish between versions, and neither requires modifications by the user. For example, a recurring model retraining, an upgraded model library, faster prediction speed, updated documentation, or other non-consumer-facing changes.
Applying semantic versioning to ML, an example
Suppose we have a model that predicts the number of customers. We serve this model internally as a REST API, which other departments use to predict revenue and decide on marketing expenses. The data scientists continuously improve the model and frequently release new versions. In recent months, they have made the following changes:
They switched from random forests to gradient-boosted trees. This change is mainly hidden from the consumers, though it should improve the performance. They proudly shared this change and started an a/b test to verify the improvement. These changes would warrant a minor version upgrade.
They also improved the logging of created predictions, allowing them to diagnose issues better and retrain new models in the features. As this doesn’t impact the model’s behavior from the consumer’s perspective, they released it as a new patch version.
The data scientists did a more extensive grid search on the model’s hyper-parameters, which theoretically resulted in a better model. This functional change is significant enough that they want to track the metrics separately per model. Therefore, they labeled the model with a new minor version. They ran the new model side-by-side in an a/b test and then switched to the latest version.
They subsequently upgraded the library of their gradient-boosted trees implementation (LightGBM) to improve runtime performance (memory and speed). As the API hides this change from the users, this was a patch version upgrade.
The data engineers found new data sources providing additional features, which the data scientists used to train a new model. To use this latest version, the callers of the REST API need to include these input features, which is a breaking change. They, therefore, released this change as a new major version. The model was served under a new REST endpoint (under /v12 instead of /v11) to allow a smooth transition.
Note that specific changes can result in a different version depending on how the model is delivered. If, for example, the model was released to (internal) customers as a serialized model, switching from a random forest to gradient-boosted trees would be a breaking change and, thus, a major version bump. In our example above, the REST API hides the implementation library from the external world, so changes in it are either minor or patch.
Afterword
A specific version can be determined sentimentally, based on some uncalibrated feeling of change size. This approach, however, isn’t explicit nor clear and prevents easy downstream decisions (and certainly automation). Semantic versioning requires more thought about the version identifier, which can feel like a wasted effort. However, this thought process improves communication by bringing explicitness to the changes, which provides easy downstream decisions. Thus, a one-time effort by the model team saves effort for all model users. Even if you don’t use the semantic version numbers, explicitly identifying upgrades as breaking changes, improvements (minor), or patches will provide clarity for all users. Either way, I’d recommend trying it, even if it is just a thought experiment.
[1]: https://semver.org/
